HBase产品新篇章 云原生多模数据库Lindorm技术解析与数据处理服务实践
在当今数据驱动的时代,企业面临着数据量激增、数据类型多样以及成本控制等多重挑战。传统的数据库解决方案往往在“存得起”与“看得见”之间难以兼顾。HBase作为经典的分布式列存储数据库,以其强大的海量数据存储与高并发读写能力著称。而阿里云基于HBase内核深度优化,推出的云原生多模数据库Lindorm,则进一步解决了多模态数据处理、弹性伸缩与成本效率等核心痛点,真正实现了让数据“既存得起,又看得见”。
一、 从HBase到Lindorm:云原生多模数据库的演进
HBase的设计初衷是应对海量结构化与非结构化数据的存储与随机实时访问。它基于HDFS,具备良好的水平扩展性和高可用性。在云原生与多模融合的趋势下,企业需求变得更加复杂:需要同时处理时序数据、时空数据、宽表数据、文档数据等多种模型,并要求极致的弹性与更低的成本。
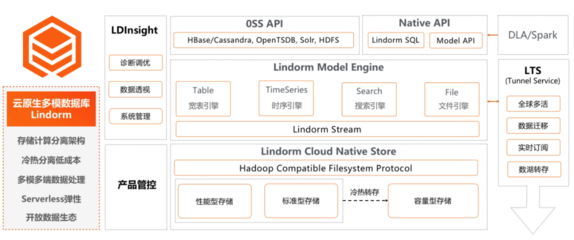
Lindorm应运而生,它继承了HBase的高性能、高可靠基因,并进行了全面的云原生架构重构。其核心在于“多模”:一个数据库引擎,原生支持宽表、时序、文件、搜索等多种数据模型,统一了数据入口,简化了技术栈。这使得开发人员无需为不同类型的数据部署和维护多套系统,极大地降低了运维复杂度和总拥有成本(TCO),从根本上让海量数据“存得起”。
二、 Lindorm核心技术解析:如何让数据“看得见”
“看得见”意味着数据不仅要存得好,更要能用得好,即具备高效的数据处理与服务能力。Lindorm通过一系列技术创新实现了这一点:
- 存储计算分离与弹性伸缩:Lindorm采用彻底的存储计算分离架构。数据持久化存储在分布式存储层(基于盘古),而计算节点(如读写节点、索引节点)则无状态化,可根据业务负载秒级弹性扩缩容。这使得企业无需为业务峰值预置大量资源,真正按需使用,成本可控。当需要执行复杂查询或分析时,可以快速扩容计算资源,让数据快速“可见”。
- 多模统一查询与索引:Lindorm内置了强大的二级索引(全局索引、局部索引)和搜索引擎(与阿里云Elasticsearch深度集成)。对于宽表数据,除了主键查询,可以通过二级索引实现灵活的多条件组合查询。对于时序数据,提供了高效的时序聚合查询。更重要的是,它支持跨模型的统一查询,例如将设备元数据(宽表)与其实时上报的指标数据(时序)进行关联分析,极大提升了数据价值的挖掘效率。
- 高性能与智能优化:Lindorm在HBase内核上做了深度优化,包括自研的LSM-Tree存储引擎、智能压缩编码、冷热数据分层等。通过智能缓存、谓词下推、向量化计算等技术,大幅提升了查询性能,尤其是复杂扫描和分析查询的速度,让大数据量的实时洞察成为可能。
- 无缝集成的数据处理服务:Lindorm并非孤立的存储系统,它提供了丰富的数据处理与服务链路。
- 数据通道:支持通过DTS、Canal等工具与MySQL、Oracle等传统数据库进行实时同步,也支持Kafka、Flink等流计算引擎直接接入,实现流批一体的数据入库。
- 计算生态集成:与Spark、Flink、Hive等大数据计算引擎无缝对接,方便进行离线数据分析、机器学习等深度数据加工。
- 数据服务化:通过HTTPSQL、JDBC等标准接口,或与API网关结合,能够将数据库中存储的数据快速、安全地以API的形式暴露给前端应用,直接驱动业务,完成从数据存储到数据服务的闭环。
三、 典型应用场景与数据处理服务实践
Lindorm的“存得起、看得见”特性,使其在物联网、金融、车联网、互联网内容等领域大放异彩。
- 物联网平台:作为设备元数据、时序指标数据的统一存储。海量设备数据以低成本存入,通过时序聚合查询实时监控设备状态,利用流计算(Flink)在Lindorm上实现实时告警,并通过数据服务API将分析结果推送到运维大屏。
- 内容推荐与搜索:存储用户画像(宽表)、内容元数据(宽表/文档)和行为日志(时序)。利用Lindorm的搜索索引实现内容的全文检索和多维度筛选,结合用户实时行为进行在线特征计算,为推荐引擎提供毫秒级延迟的数据服务。
- 金融风控:存储交易流水、用户账户信息。利用二级索引快速定位可疑交易,通过Spark进行离线批量风险建模,模型结果回写至Lindorm,为在线风控系统提供实时查询服务。
###
云原生多模数据库Lindorm,代表了大数据存储与处理技术的一个重要发展方向。它根植于HBase的坚实土壤,通过云原生、多模融合、存算分离、智能索引等关键技术,构建了一个高弹性、低成本、强性能的统一数据底座。这不仅解决了海量数据“存得起”的经济性问题,更通过强大的内置处理能力和开放的计算生态,让数据价值能够被高效地“看得见”、用得上,赋能企业构建敏捷、智能的数据驱动型应用。在数字化转型的深水区,Lindorm这样的技术正成为企业释放数据潜能的关键基础设施。
如若转载,请注明出处:http://www.zhihongsite.com/product/80.html
更新时间:2026-06-18 16:58:24